
When AI Data Scraping Causes Problems for Digitized Archives
This summer one of my favorite archival websites was hit by so much AI bot traffic it amounted to a denial of service. Which is bad, because the Hagley Digital Archives are awesome.

Several months ago, when I was starting this blog, there was one particular archive I knew I needed to include. The Hagley Library Digital Archives are an incredible trove, especially for media historians and historians of business, technology and society.
Be warned: Just browsing the Hagley’s Digital Archives will send you down the rabbit hole. Once you click over, and browse, I’d guess you’ll be spending more time looking around then you think.
In late June, I went to the Hagley Library website to create a post, and was greeted by the following notice on the landing page:

The Hagley Library was facing unprecedented amounts of web scraping. It turns out, they weren’t alone. A viral video of Matthew Prince, the CEO of Cloudflare (one of the biggest web hosting companies), speaking in Cannes in May, explained the situation. It’s a fascinating story, told in the first four minutes of this video below.
The short version (if you don’t want to click on this video) is simple: So much AI scraping is occuring that the traffic ratio for web creators (and publishers) is getting insane. Tens of thousands of phantom visitors (really bot scrapers from AI companies) are regularly hitting websites to use their data to train AI models.
In other words: Google is visiting, scraping, and training its AI on webpages’ public data, and then not sending people using Google search (or AI) back to that page. Instead, Google’s now answering search queeries using AI summaries right at Google. That means just about every webpage is getting tens of thousands of daily phantom visitors, while real people looking for webpages and links are being held at Google.
If it sounds nefarious, that’s because it is. And Google is only one of several companies training its AI this way.
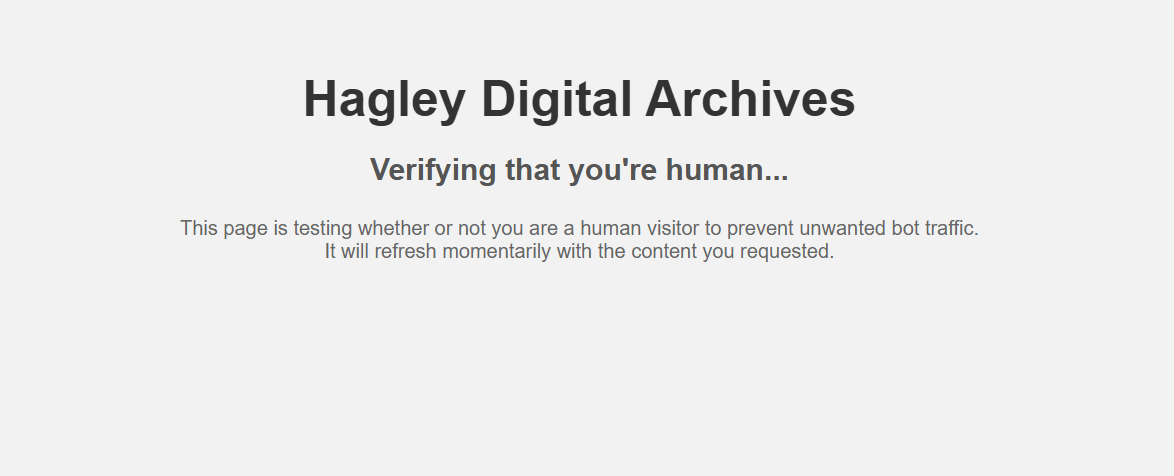
That’s why a recent queery for a specifc item I knew existed in the Hagley Digital Archive resulted in this page popping up (to deter bots):
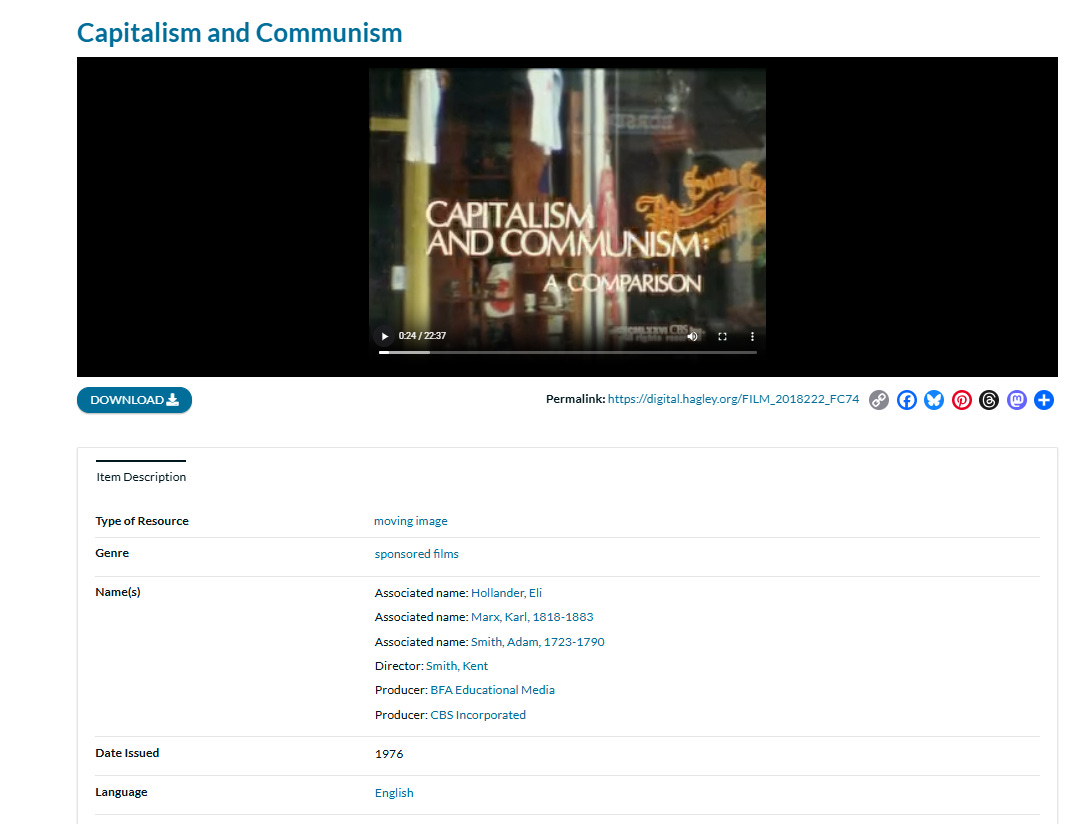
Anyway: I’m glad to see that now, it appears, the Hagley Library has sorted out the problem somewhat. You can now browse the archives for all kinds of cool and unexpected things - like a 22-minute “educational” film made in 1976 by CBS in conjunction with BFA Educational Media and universities in Yugoslavia and California titled “Capitalism and Communism: A Comparison.”
There’s much historical and archival material to consider, but I’ll leave you with this, since it’s football season: A promotional video for CBS’s coverage of the NFL in the late 1960s, made by a vendor (Cinecraft Production Films) for CBS and the National Football League to entice advertisers to purchase commercials on football on TV
Credit: CBS Sports football promotion. (n.d.). In Cinecraft Productions films. Audiovisual Collections, Hagley Museum and Library. Retrieved August 31, 2025, from https://digital.hagley.org/FILM_2019227_FC276_05 (Original work published 1970)
Once again: Here’s how to browse the archive by subject. Enjoy!